Vida de un objeto URLRequest¶
Este documento es una traducción del siguiente documento: Life of a URLRequest - The Chromium Project (24/03/2020)
La versión más actualizada del documento (en inglés) se puede encontrar aquí.
Este documento tiene como objetivo exponer las capas centrales de la pila de red y el servicio de red de Chrome, sus responsabilidades básicas, y cómo encajan juntas, sin dar mucho detalle. Este documento asume que el servicio de red está activado, aunque el servicio de red no está todavía activado por defecto en todas las plataformas.
Está dirigido principalmente a las personas nuevas a la pila de red de Chrome, pero también debería ser útil para miembros del equipo que sean expertos en algunas partes de la pila, pero que no estén tan familiarizados con otros componentes. Empieza explicando cómo una petición básica que realiza otro proceso se desplaza por la pila de red, y después habla también sobre cómo varios componentes están integrados en ella.
Anatomía de la pila de red¶
La pila de red está ubicada en //net/ en el repositorio de Chrome, y usa el espacio de nombres net. Cuando no se especifique en qué espacio de nombres está una clase en este documento se puede asumir generalmente que está en //net/ y en el espacio de nombres net.
El objeto de arriba del todo de la pila de red es URLRequestContext. El contexto tiene punteros non-owning para todo lo que se necesita para crear y emitir un URLRequest. El contexto debe durar más tiempo que todas las peticiones que lo usan. Crear un contexto es un proceso bastante complicado, así que se recomienda que la mayoría de los consumidores usen URLRequestContextBuilder para hacer esto.
El uso principal de URLRequestContext es crear objetos URLRequest usando URLRequestContext::CreateRequest(). URLRequest es la interfaz principal usada por los consumidores directos de la pila de red. Se usa para conducir peticiones para http, https, ftp, y algunas URLs data. Cada URLRequest se encarga de seguir una sola petición a través de todas las redirecciones hasta que ocurre un error, se cancela o se recibe una respuesta final, con un cuerpo (posiblemente vacío).
HttpNetworkSession es otro de los objetos de la pila de red más importantes. Es propietario de HttpStreamFactory, las piscinas de sockets, y las piscinas de sesiones de HTTP/2 y QUIC. También tiene punteros non-owning a los objetos de la pila de red que trabajan más directamente con los sockets.
Este documento no menciona mucho ninguno de los dos, pero en capas por encima de HttpStreamFactory, los objetos tienden a coger sus dependencias de URLRequestContext, mientras que la capa de HttpStreamFactory y capas inferiores generalmente cogen sus dependencias de HttpNetworkSession.
¿Cuántos "delegados" hay?¶
Una URLRequest informa al consumidor de eventos importantes de una petición usando dos interfaces principales: la interfaz URLRequest::Delegate y la interfaz NetworkDelegate.
La interfaz URLRequest::Delegate consiste de un pequeño conjunto de callbacks que se necesitan para permitir que el embededor conduzca una petición adelante. NetworkDelegate es un objeto apuntado por URLRequestContext y compartido por todas las peticiones, e incluye callbacks correspondientes a la mayoría de los callbacks de URLRequest::Delegate, además de un surtido de otros métodos.
El servicio de red y Mojo¶
El servicio de red, que vive en //services/network/, envuelve objetos //net/ y proporciona APIs de red cross-process y sus implementaciones para el resto de Chrome. El servicio de red usa el espacio de nombres network para todas sus clases. Las interfaces Mojo que proporciona están en el espacio de nombres network::mojom. Mojo es la capa IPC de Chrome. Generalmente hay un objeto proxy network::mojom::FooPtr en el proceso del consumidor que también implementa la interfaz network::mojom::Foo. Cuando los métodos del objeto proxy se invocan, pasa la llamada y todos sus argumentos por un canal Mojo IPC a otra implementación de la interfaz network::mojom::Foo en el servicio de red (típicamente implementado por una clase llamada network::Foo), que puede estár ejecutándose en otro proceso o posiblemente otro subproceso del proceso del consumidor.
El objeto network::NetworkService es un singleton que es usado por Chrome para crear todos los otros objetos del servicio de red. Los objetos principales que está habituado a crear son network::NetworkContexts, cada uno de los cuales es propietario de su propio URLRequestContext independiente. Chrome tiene varios NetworkContexts diferentes, ya que a menudo hay la necesidad de mantener cookies, cachés y piscinas de sockets separados para diferentes tipos de petición, dependiendo de qué está haciendo la petición. Aquí hay los NetworkContexts más comunes usados por Chrome:
- El sistema
NetworkContext, creado y propiedad delSystemNetworkContextManagerde Chrome, se usa para peticiones que no están asociados a un usuario en particular o perfil. No tiene espacio de almacenamiento en disco, así que pierde su estado, como las cookies, después de cada reinicio del navegador. No tiene caché http en memoria tampoco.SystemNetworkContextManagertambién establece preferencias del servicio de red globales. - Cada perfil de Chrome, incluyendo los perfiles de incógnito, tienen su propio
NetworkContext. Exceptuando los perfiles de incógnito e invitado, estos contextos guardan información en su propio espacio de almacenamiento en disco, que incluye cookies y un caché HTTP, a parte de otras cosas. Cada uno de estosNetworkContextspertenece a un objetoStoragePartitionen el proceso del navegador y es creado por elProfileNetworkContextServicedel perfil. - En las plataformas que soportan las aplicaciones, cada perfil tiene un
NetworkContextpara cada aplicación instalada en ese perfil. Como con elNetworkContextprincipal, estos pueden tener datos en disco, dependiendo del perfil y la aplicación.
Vida de un URLRequest simple¶
Una petición de información se despacha de algún otro proceso que resulta en la creación de un network::URLLoader en el proceso de red. El URLLoader entonces crea un URLRequest para conducir la petición. Un trabajo (job) específico para el protocolo (por ejemplo HTTP, data, file) se adjunta a la petición. En el caso de HTTP, ese trabajo primero comprueba la caché, y luego crea un objeto de conexión de red, de ser necesario, para obtener la información. Ese objeto de conexión interactúa con la piscina de sockets de red para reusar potencialmente sockets; la piscina de sockets crea y conecta un socket si no existe un socket apropiado. Una vez ese socket existe, la petición HTTP se despacha, la respuesta se lee y se procesa, y el resultado se devuelve de nuevo a la pila y se envía al proceso hijo.
Por supuesto, esto no es tan sencillo :-}.
Consideremos una petición sencilla creada por algún proceso otro que el proceso del servicio de red. Supongamos que es una petición HTTP, la respuesta no está comprimida, no hay una entrada coincidiente en la caché y no hay sockets libres conectados al servidor en la piscina de sockets.
Continuando con la URLRequest "simple", aquí hay un poco más de detalle sobre cómo funcionan las cosas:
La petición empieza en algún proceso (no de red)¶
Resumen:
- Un consumidor (por ejemplo
content::ResourceDispatcherpara Blink,content::NavigationURLLoaderImplpara navegación en frame, onetwork::SimpleURLLoader) pasa un objetonetwork::ResourceRequesty un canal Mojonetwork::mojom::URLLoaderClientanetwork::mojom::URLLoaderFactory, y le dice de crear e iniciar unnetwork::mojom::URLLoader. - Mojo envía
network::ResourceRequestpor un pipe IPC a unnetwork::URLLoaderFactoryen el proceso de red.
Chrome tiene un solo proceso del navegador que se encarga de iniciar y configurar otros procesos, la gestión de las pestañas, la navegación, etc., y varios procesos hijos, que generalmente están en una caja de arena y no tienen acceso a la red por ellos mismos, a parte del servicio de red (que o bien se ejecuta en su propio proceso, o potencialmente se ejecuta en el proceso del navegador para conservar RAM). Hay varios tipos de procesos hijos (renderizador, GPU, complementos, red, etc). Los procesos de renderizador son los que maquetan las páginas web y ejecutan el HTML.
El proceso del navegador crea los objetos de nivel superior network::mojom::NetworkContext y los usa para crear network::mojom::URLLoaderFactories, a los cuales les puede activar algunas opciones relacionadas con la seguridad, antes de dárselas a los procesos hijos. Los procesos hijos pueden luego usarlos para hablar directamente con el servicio de red.
Un consumidor que quiere hacer una petición de red obtiene un URLLoaderFactory de alguna manera, ensambla unos cuantos parámetros en el objeto grande ResourceRequest, crea un canal Mojo network::mojom::URLLoaderClient para que network::mojom::URLLoader lo use para hablar de vuelta a él, y después los pasa a URLLoaderFactory, que devuelve un objeto URLLoader que puede usar para gestionar la petición de red.
network::URLLoaderFactory configura la petición en el servicio de red¶
Resumen:
network::URLLoaderFactorycrea unnetwork::URLLoader.network::URLLoaderusa elURLRequestContextdenetwork::NetworkContextpara crear e inicar unaURLRequest.
URLLoaderFactory, junto a todos los NetworkContexts y la mayoría de la pila de red, vive en un solo subproceso en el servicio de red. Obtiene un objeto reconstituido del pipe de Mojo, hace algunas comprobaciones para asegurarse que puede atender la petición y si es así, crea un URLLoader, pasando la petición y el NetworkContext asociado con el URLLoaderFactory.
URLLoader entonces llama un URLRequestContext para crear la URLRequest. URLRequestContext tiene punteros a todos los objetos de la pila de red que necesita para realizar la petición en la red, como por ejemplo la caché, el almacenamiento de cookies, y el host resolver. URLLoader entonces llama a ResourceScheduler, que puede retrasar el inicio de la petición basándose en su priodidad y otra actividad. Eventualmente, ResourceScheduler inicia la petición.
Comprobación de la caché, petición de un HttpStream¶
Resumen:
URLRequestpide aURLRequestJobFactoryque cree unURLRequestJob, en este caso, unURLRequestHttpJob.URLRequestHttpJobpide aHttpCachede crear unHttpTransaction(siempre unHttpCache::Transaction).HttpCache::Transactionve que no hay una entrada de caché para la petición, y crea unHttpNetworkTransaction.HttpNetworkTransactionllama aHttpStreamFactorypara pedir unHttpStream.
URLRequest entonces llama a URLRequestJobFactory para crear un URLRequestJob y entonces lo inicia. En el caso de una petición HTTP o HTTPS, ese será un URLRequestHttpJob. URLRequestHttpJob adjunta las cookies a la petición, si es necesario.
URLRequestHttpJob llama a HttpCache para crear un HttpCache::Transaction. Si no hay una entrada coincidiente en la caché, HttpCache::Transaction llamará a HttpNetworkLayer para crear un HttpNetworkTransaction, y transparentemente lo envolverá. HttpNetworkTransaction entonces llama a HttpStreamFactory para pedir un HttpStream al servidor.
Creación de un HttpStream¶
Resumen:
HttpStreamFactorycrea unHttpStreamFactory::Job.HttpStreamFactory::Jobllama aTransportClientSocketPoolpara rellenar unClientSocketHandle.TransportClientSocketPoolno tiene sockets libres, así que crea unTransportConnectJoby lo inicia.TransportConnectJobcrea unStreamSockety establece una conexión.TransportClientSocketPoolpone elStreamSocketen elClientSocketHandle, y llama aHttpStreamFactory::Job.HttpStreamFactory::Jobcrea unHttpBasicStream, que se convierte en el propietario delClientSocketHandle.- Devuelve el
HttpBasicStreamalHttpNetworkTransaction.
HttpStreamFactory::Job crea un ClientSocketHandle para tener el socket, una vez conectado, y pasarlo a ClientSocketPoolManager. ClientSocketPoolManager ensambla el TransportSocketParams requerido para establecer la conexión y crea un nombre de grupo ("huésped:puerto") usado para identificar los sockets que se pueden usar intercambiablemente.
ClientSocketPoolManager dirige la petición a TransportClientSocketPool, ya que no hay ningún proxy y es una petición HTTP. La petición se reenvía al ClientSocketPoolBaseHelper de ClientSocketPoolBase<TransportSocketParams> de la piscina. Si no hay aún una conexión libre, y hay ranuras de sockets disponibles, ClientSocketPoolBaseHelper creará un nuevo TransportConnectJob usando el objeto de parámetros anteriormente mencionado. Este trabajo hará la consulta de DNS llamando a HostResolverImpl, de ser necesario, y después finalmente establecerá una conexión.
Una vez el socket está conectado, la propiedad del socket se pasa al ClientSocketHandle. HttpStreamFactory::Job es entonces informado de que el intento de conexión ha sido satisfactorio, y entonces crea un HttpBasicStream, que toma la propiedad del ClientSocketHandle. Este entonces pasa la propiedad de HttpBasicStream de vuelta al HttpNetworkTransaction.
Envía la petición y lee las cabeceras de la respuesta¶
Resumen:
HttpNetworkTransactionda las cabeceras de la petición alHttpBasicStream, y le dice que inicie la petición.HttpBasicStreamenvía la petición, y espera la respuesta.HttpBasicStreamenvía las cabeceras de la respuesta de vuelta aHttpNetworkTransaction.- Las cabeceras de la respuesta se envían mediante la
URLRequestalnetwork::URLLoader. - Se envían después al
network::mojom::URLLoaderClientmediante Mojo.
El HttpNetworkTransaction pasa las cabeceras de la petición al HttpBasicStream, que usa un HttpStreamParser para (finalmente) formatear las cabeceras de la petición y el cuerpo (si está presente) y enviarlos al servidor.
HttpStreamParser espera recibir la respuesta y entonces procesa las cabeceras de respuesta HTTP/1.x, y luego las pasa mediante ambos el HttpNetworkTransaction y HttpCache::Transaction al URLRequestHttpJob. URLRequestHttpJob guarda algunas cookies, si es necesario, y entonces pasa las cabeceras arriba a la URLRequest y después al network::URLLoader, que envía la información por un pipe de Mojo al network::mojom::URLLoaderClient, pasado al URLLoader cuando fue creado.
Se lee el cuerpo de la respuesta¶
Resumen:
network::URLLoadercrea un pipe de datos de Mojo raw, y pasa un extremo alnetwork::mojom::URLLoaderClient.URLLoaderpide un buffer de memoria compartida del pipe de datos de Mojo.URLLoaderdice alURLRequestde escribir al buffer de memoria, y le dice al pipe cuando la información se ha escrito al buffer.- Los últimos dos pasos se repiten hasta que la petición se completa.
Sin esperar a oír de vuelta del network::mojom::URLLoaderClient, el network::URLLoader asigna un pipe de datos de Mojo raw, y pasa al cliente el extremo de lectura del pipe. URLLoader entonces coge un buffer IPC del pipe, y pasa una lectura de 64KB del cuerpo de la respuesta hacia abajo al URLRequest hasta abajo del todo, al HttpStreamParser. Una vez un poco de información ha sido leída, posiblemente menos de 64KB, el número de bytes leídos va de vuelta al URLLoader, que entonces le dice al pipe de Mojo que la lectura ha sido completada, y entonces pide otro buffer del pipe, que continúa escribiéndole información. El pipe puede aplicar presión hacia atrás, para limitar la cantidad de información no consumida que puede estar en los buffers de memoria compartida a la vez. Este proceso se repite hasta que el cuerpo de la respuesta se lee completamente.
URLRequest is destroyed¶
Resumen:
- Cuando se completa,
network::URLLoaderFactoryelimina elnetwork::URLLoader, que elimina laURLRequest. - Durante la destrucción, el
HttpNetworkTransactiondetermina si el socket es reutilizable, y en ese caso le dice alHttpBasicStreamde devolverlo a la piscina de sockets.
Cuando el URLRequest informa al network::URLLoader que la petición se ha completado, el URLLoader pasa el mensaje hacia el network::mojom::URLLoaderClient, a través de su pipe de Mojo, antes de decirle al URLLoaderFactory de destruir el URLLoader, lo que resulta en la destrucción del URLRequest y el cierrede todos los pipes de Mojo relacionados con la petición.
Cuando el HttpNetworkTransaction se está destruyendo, este determina si el socket es reutilizable. Si no, le dice a HttpBasicStream de cerrarlo. En cualquier caso, el ClientSocketHandle devuelve el socket a la piscina de sockets, ya sea para su reutilización o para que la piscina de sockets sepa que tiene otra ranura disponible.
Relaciones entre objetos y propietarios¶
Un ejemplo de las relaciones entre objetos involucrados en el proceso de arriba se muestre en el siguiente diagrama:
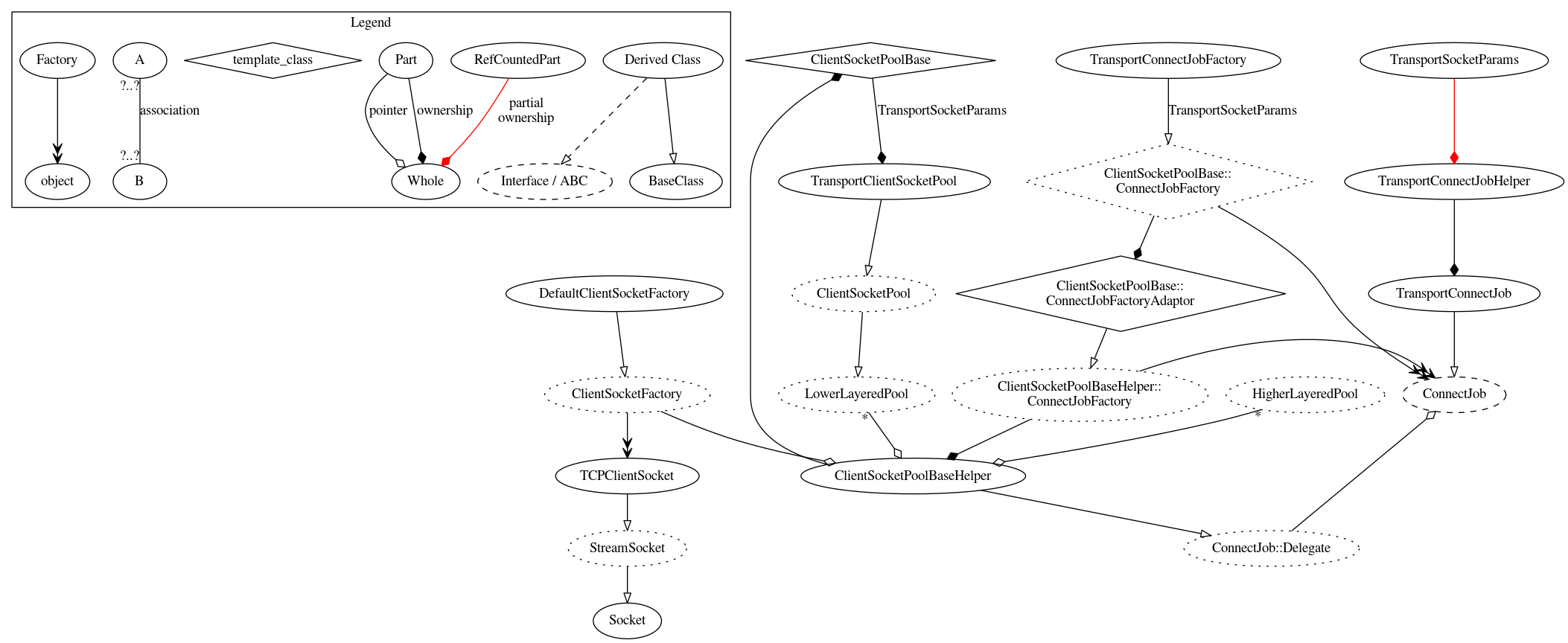
Hay dos cosas del diagrama anterior que no se hacen claras visualmente:
- El método que genera la cadena de filtrado que cuelga del
URLRequestJobestá declarado enURLRequestJob, pero la única implementación actual de esta está enURLRequestHttpJob, así que la generación está mostrada como ocurre desde esa clase. - Las
HttpTransactionsde diferentes tipos están en capas. Es decir, unaHttpCache::Transactioncontiene un puntero a unaHttpTransaction, pero eseHttpTransactionque está siendo apuntado es generalmente unHttpNetworkTransaction.
Temas adicionales¶
Falta la traducción
Esta sección no ha sido traducida, pero se puede consultar en el documento original (en inglés) enlazado al principio de este documento.